
The increased availability of data and computing power, combined with ongoing advances in the field of artificial intelligence (AI), have led to significant improvements in the ability to solve problems using smart devices powered by machine learning algorithms.
These advances are particularly important when it comes to data related to issues that are critical to people’s well-being, such as health and safety.
We now know that information and accumulated knowledge, when held by a single organization, are inefficient because, if shared, they can help solve various problems.
In fact, for several years now, various NGOs and research institutes have been advocating for greater data sharing, based on the understanding that if organizations shared their knowledge by exchanging raw data or predictive models trained on that data, progress would be more comprehensive and efficient.
One possible approach to this problem is Differential Privacy (DP), “a general mathematical framework based on quantifying privacy loss as a random variable, whose goal is to enable the design of specific mechanisms that provide data protection by demonstrably limiting privacy loss to a desired amount with a given level of confidence,” explains Dr. Sergio Yovine, head of the Artificial Intelligence and Big Data Chair at the School of Engineering at ORT University in Uruguay.
Common Data Management and Privacy
Although data anonymization techniques exist and are used, the results are not always as expected because the risks posed by potential attacks remain and are intensifying worldwide.
This reality leads us to continue exploring alternatives, and thus DP emerges—a framework based on mathematical guarantees that allows us to adjust various parameters to create a solution and validate its compliance with the requirements of the proposed mathematical framework. In other words, DP is underpinned by a mathematical theory that supports its functionality.
As Ramiro Visca, an engineer and member of the research team at ORT’s Artificial Intelligence and Big Data Department and a fellow at the ICT4V technology center, points out, the key lies in the fact that this framework proposes a definition that sets out mathematical guidelines to be followed, and privacy mechanisms must then be designed that can demonstrate compliance with the mathematical framework established by the DP.
“It’s quite a difficult task; it doesn’t happen overnight, because the mathematical definition is quite cumbersome, the concept is complex to understand, and it’s even harder to find a mechanism that can be proven and that fits within the mathematical framework. It’s not an easy tool to use,” warns Visca.

Despite the difficulties, it is the mathematical guarantee that validates and strengthens the DP’s capability, “because it essentially establishes a parameter called ε, which, if it equals 0, indicates that the data is being anonymized 100%. In a dataset, if I run a query on it, having that ε set to 0 guarantees that I am not leaking information. In other words, I have the utopia of the perfect mechanism that allows me to release the dataset without worrying about privacy being violated,” the researcher states.
For Visca, beyond the individuals who own the information, the role of data for organizations “in the best-case scenario is to assist them in decision-making, or to help them gain a competitive advantage in terms of innovation.”
“I think organizations aren’t aware of the need to manage data privacy, even beyond the existence of laws. The vast majority of organizations do not consider privacy when designing their systems. Otherwise, we wouldn’t be discussing this issue, because everything would be designed around this concept, and essentially what we’re doing now is trying to patch up the problem with post-data-collection privacy mechanisms,” Visca emphasizes.
“Within what is considered data protection, there are two types: one is the centralized or global model, which aims to protect an entire database; and then there is the local model, which states that as the database is being built, I apply a privacy filter from the outset. So, by the time I’ve built that database, I already know it meets the definition of data protection,” he adds.
Pros and cons
For Eduardo Giménez, a member of the ICT4V Operations Team, DP is a theoretical framework that provides “a precise and elegant answer” to the question of what data privacy is.
“He’s right to view this issue as a characteristic of the software itself, rather than of the data, as is usually the case. He’s setting ambitious goals, such as making the system resistant to any kind of privacy attack,” he notes.
However, Giménez explains that, even without being an expert in this technique, certain aspects of it make it difficult to apply in practice. One of these is that it introduces the concept of a “privacy budget,” the appropriate value of which is very difficult to estimate in advance. When conducting a data science experiment, you don’t fully know what you’re looking for beforehand, and it’s necessary to perform many tests and adjustments before finding the predictive model you need or fine-tuning it to the desired point. Along the way, it’s very possible that you’ll exhaust your “privacy budget.”
Another challenge with DP is that it does not allow for the free combination of sub-problems to derive new ones; rather, one must be careful about how these combinations are made so as not to lose the expected properties.
All of this requires specialized technicians who have a thorough understanding of DP technology and its definitions, and such professionals are in short supply on the market.
“I think it’s more likely that this technology will be used as part of a service that integrates and bundles it. For example, at PedidosYa, the data lake used for business intelligence operations is hosted on Google Cloud. There’s a chance that DP could be used if Google integrates it into BigQuery,” concludes Giménez.
Progressive legal framework
In our country, the handling of personal data is governed by Law No. 18,331, which recognizes the right of individuals to control how their personal information—recorded in any medium that allows it to be processed and subsequently used in various ways—is handled, both in the private and public sectors.
This law was amended in 2018 by Articles 37 through 40 of Law No. 19,670, which introduced the principle of proactive accountability, the role of the data protection officer (Agesic), security breach notifications (CERTuy), and an expansion of the law’s territorial scope.
Subsequently, in December 2020, Articles 86 and 87 of Law No. 19,924 included a definition of biometric data and specific conditions for its processing, as noted by Agesic.
Efforts focused on data protection began in 2018 with the development of the National Data Strategy and Policy, which laid the groundwork for public agencies to follow and for the formulation of public policies, while also establishing principles for the development of projects involving the intensive use of data, which explicitly include the protection of personal data and data security.
Uruguay has robust legal framework for the protection of personal data, with standards similar to those of the European Union.
Javier Barreiro, an engineer and manager of IUGO Software & Design Studio and former Chief Technology Officer at Agesic—where he helped develop strategies for AI implementation in Uruguay—believes that one of the key aspects of the policy is that it followed a public consultation process from the outset, with an initial draft prepared by a multidisciplinary team.
This team based its analysis on the experiences of other leading countries in this field, such as Canada and Italy, and then adapted it to local conditions and regulations.
“The public consultation allowed us to gather feedback from civil society, international organizations, government agencies, and citizens. Each comment was analyzed, and either incorporated into the strategy or addressed in a response to the person who submitted it,” he says.
According to Barreiro, the strategy outlined from the outset took into account the need to preserve data, and this approach was reflected in the general principles and specific objectives.

The multidisciplinary nature of the team was key, he says. “From a regulatory standpoint, Uruguay has cutting-edge has is aligned with European data protection standards. The biggest challenge will likely be how to effectively implement these regulations—both to ensure compliance and to build capacity among stakeholders to address them,” he notes.
Agesic notes that Uruguay is the country with “the highest level of maturity in the region across four of the five dimensions measured,” according to the second edition of the “2020 Cybersecurity Report: Risks, Progress, and the Way Forward in Latin America and the Caribbean,” prepared by the IDB and the OAS.
Furthermore, the country ranks among the top nations in the Americas according to the Global Cybersecurity Index (GCI), compiled by the International Telecommunication Union (ITU), placing third in 2018 behind the United States and Canada.
Qualified human resources
One of the biggest challenges facing the world today is the shortage of qualified cybersecurity professionals and technicians.
To this end, Agesic is working with various stakeholders to support the development of cybersecurity curricula in schools across the country, as well as to promote the creation of a nationwide network of experts that includes all relevant parties.
One of the biggest challenges facing the world today is the shortage of qualified cybersecurity professionals and technicians.
With regard to the DP, Agesic believes that one of its advantages lies in the fact that datasets are provided to authorized third parties in response to a specific request, rather than simply as a result of the publication of a single dataset.
From a data protection perspective, the greatest challenge is the ability to generate the right amount of noise (it is necessary to generate a significant amount of noise, as failing to do so is a common mistake), which is added to the true responses in order to protect individuals’ privacy while preserving the usefulness of the published responses.
Furthermore, care must be taken not to fall into the trap of assuming that the data is anonymous to third parties when the data controller can still identify the data subject in the original database using all means that can reasonably be employed.
Agesic officials also note that this technique, along with others, is among those specified by the Personal Data Regulatory and Control Unit in Resolution No. 68/017, which approved the document “Criteria for the De-identification of Personal Data.” This document was drafted in accordance with the provisions of Decree No. 54/017, which implements Article 82 of Law No. 19,355, establishing that public entities subject to Law No. 18,381 and Decree No. 232/010 must provide data in open data format.
Data Open to Innovation
Returning to the issue of data privacy and security, from the perspective of researchers and professionals, the requirement to share data is driven not only by legislation but also by the need to make it available to public and private stakeholders with the technical capacity to use it for scientific and technological innovation.
For Sabrina Lanzotti, one of the first graduates of the Master’s in Big Data program at Universidad ORT Uruguay currently head of the DevSecOps Technical Team at Atos, information security management is essential in today’s environment, where many organizations recognize the value of proper information security management.
Despite this recognition, the response is largely reactive, because “some organizations have not yet achieved maturity in their management systems despite having implemented technical measures to protect their assets,” he says.

It also notes that certain frameworks widely used in the industry include the ISO 27000 series of standards, the NIST Cybersecurity Framework, and the AGESIC Cybersecurity Framework, among others, and that all of them “are based on understanding what assets we have, what value they hold for our organization, how we are exposed to risks, the implementation of measures to mitigate those risks, and continuous improvement.”
In this context, Lanzotti believes that DP is an effective technique for learning everything about customers without putting them at risk.
“It allows us to gather a lot of information about a group but not about its individual members. In an initial attempt to process large volumes of personal data without identifying individuals, one might remove data that at first glance would seem to solve the problem—such as names, ID numbers, addresses, and so on. However, re-identification techniques have shown that this is not enough. Differential privacy mathematically ensures that this doesn’t happen by adding randomness and noise. Companies like Google and Apple already use it in their products,” explains Lanzotti.
Local businesses
Drawing on his experience as Head of Security at PedidosYa, Eduardo Giménez notes that all decisions made in this area must take into account the fact that the company is growing at an exponential rate year after year—not in a metaphorical sense, but literally: each year, the number of orders doubles compared to the previous year, and this has been the case for several years now.
This reality makes it necessary to prioritize automated solutions over manual ones, since the latter do not scale effectively. “At the same time, we cannot deploy security solutions that hinder that progress. We must always seek a proper balance between risk and business growth,” Giménez points out.
For this reason, the company does not currently use DP techniques. “I believe that at PedidosYa we are a long way from doing so; our privacy challenges at the moment are much more basic: how to properly comply with regulations, how to ensure that when a user requests to be removed from our systems, they are removed from ‘all’ systems, how to anonymize their data while knowing that we must retain other data related to their purchases for business reasons, how to ensure that the anonymization techniques we use cannot be exploited by attackers seeking to cover their tracks after committing fraud, and how to limit developers’ access to user data when providing support to resolve a bug.”

According to Soledad Rivas, Head of Machine Learning at Tryolabs, when working with datasets containing sensitive information, “one must be aware that safeguarding privacy is the responsibility of whoever is implementing the solution. Furthermore, one must consider the legal and ethical consequences that could arise if privacy safeguards are not in place.”
Rivas states that while efforts have been made to address this issue at the national level in recent years, “the pandemic has shown us that we still have a long way to go; that is why we believe it is essential to continue researching this problem in order to achieve better results in the future.”
This situation inspired Sebastián Sosa, a machine learning engineer at Tryolabs, to write his bachelor’s thesis in Systems Engineering at ORT, under the supervision of Ramiro Visca and Sergio Yovine. “I decided to undertake a research thesis to understand how to apply techniques that enable the training of machine learning models using sensitive data while ensuring robust privacy safeguards,” he explains.
The research
Research conducted within the Artificial Intelligence and Big Data Chair at ORT’s School of Engineering focuses on exploring a machine learning model training technique called PATE (Private Aggregation of Teacher Ensembles) to understand how it can be applied in a context different from that proposed by the original authors.
The PATE technique allows a model to be trained using a dataset containing sensitive information, while providing robust privacy guarantees expressed in terms of DP.
According to Sosa, “the contribution of this research was to extend the PATE technique to demonstrate that it is possible to train the model in contexts where the training data is sensitive, rather than public. This makes it possible to use this technique in contexts where it was not previously possible. In our particular case, we wanted to train predictive models using sensitive data belonging to a government organization, with rigorous safeguards ensuring that the privacy of this data would not be compromised.”
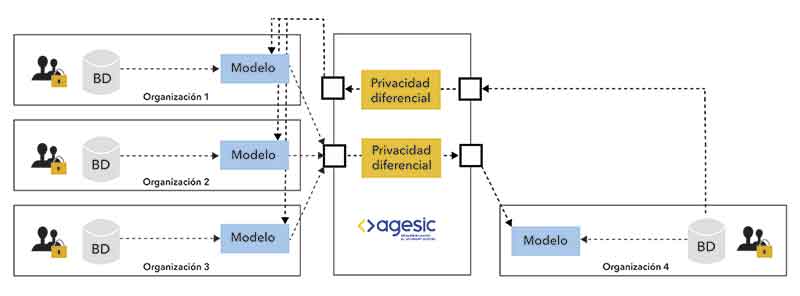 Organizations 1 through 3 (public agencies, mutual insurance companies, etc.) make their AI models—trained using their own data—available to Agesic, an entity they trust.
Organizations 1 through 3 (public agencies, mutual insurance companies, etc.) make their AI models—trained using their own data—available to Agesic, an entity they trust.
Agesic provides access to these models through a data protection mechanism that safeguards the data of Organizations 1 through 3. Organization 4 wants to build its own AI but does not have enough of its own data to do so and does not want to share its private data with the other organizations.
This organization sends its data to Agesic, which it trusts. Before querying the AI models of the other organizations, Agesic applies a data protection mechanism to safeguard Organization 4’s data. In this way, it can access the knowledge of those organizations without compromising the privacy of any of the participating organizations’ information.
“What we proposed is a hybrid privacy model. For organizations 1 through 3, this technique provides a centralized model, while for organization 4 it is a local model,” explains Franz Mayr, a doctoral student and researcher in the Department of Artificial Intelligence and Big Data at the ORT School of Engineering.
“The experimental results in cybersecurity applications (detecting attacks on web logs) and healthcare (identifying heart conditions in electrocardiograms) were very positive,” concludes Yovine.